
Register for free to receive our newsletter, and upgrade if you want to support our work.
Digital streaming platforms (DSPs) are mighty. The best known player is obviously Spotify. They manage an enormous amount of data: user, behavior, and the music itself. Distributors are constantly uploading tons of new music to these platforms. Ideally, DSPs would act as lighthouses, given their position and resources, and one would expect them to be innovators of the digital music industry –not only in terms of profit-optimisation and pricing models. In this article, we explore some recent work carried out by Deezer Research, the innovation lab of Deezer, a Paris-based DSP with around 90M tracks and over 10M users. We present some of their latest results on challenging the current practices of genre tagging, tonality estimation, AI-music detection, and recommendations.
The infamous “algorithm” has become a common point of reference to blame stuff on. It’s also a riskless source of criticism as most popular DSPs and similar platforms are closed source software systems, meaning that users cannot check the implementation of the algorithm; hence, no user can be made liable for claims made on the performance and perceived quality of the service. It’s not always the case though. For example, one of the big blows around the emergence of DeepSeek (ChatGPT’s unexpected Chinese competitor) was that it published its code, and so, in theory, people could check what’s under the hood. Not that most people could or want to realistically double check anything in such a complicated code base, but some experts could and will, and then they could and also will share condensed findings, trends, and revelations of the product, which is not only empirically but also factually true. While Deezer’s implementation is not open source, they do share results of their internal research activities via research papers.
One of the basic activity of academic and industrial research is the publication of scientific papers (typically 2-10 page write-ups with a lot of text, some graphs, tables, and other forms of visualising content) that are reviewed by a group of researchers (professors etc.) called program committees, and then presented by the authors at conferences all over the world, and formally published in so called proceedings (a “book” of the conference). If the research includes software, which is pretty much inevitable in the case of DSPs (being digital), research papers are expected to present transparent and reproducible results of the proposed system. The main platform to share such data is currently GitHub, by the way, owned by Microsoft since 2018. A GitHub project can be private (closed source) or public (open source); since research is often funded by taxpayers' money and/or it enables collaboration within the research community, GitHub projects shared in research papers tend to be public. It’s also a general positive message, e.g. by Deezer, to share seemingly edgy stuff around their core business for transparency, trust, and professional community building.
Music tagging: How to learn it efficiently?
DSPs apply auto-tagging to help their users navigate through music assets (tracks, albums, etc.). In theory, an efficient and widespread method of training AI models is called supervised learning, where training data is labeled with the ground truth. In the case of genre tagging, the dataset used for training contains pairs of a track and a set of tags describing the track. For example, the track “aphex_s950tx16wasr10.mp3” may be labelled with “idm” and “drum programming”. When a supervised AI model sees a lot of such examples, and by a lot I mean a lot (hundreds of thousands, and the more the better), then it can learn to predict genres. The problem with this approach is that labeled data is often hard to get, especially if it’s niche and/or it requires expert knowledge. As a result, because the model only sees little and/or wrongly labeled data, its accuracy (the ability to correctly auto-predict tags) will be poor.
This is where self-supervised learning can help. The main idea is that the AI model utilizes unlabeled data to learn an intermediate mathematical representation (also called embedding) of the input (e.g. tracks) so that this representation is easier to classify with respect to the original task (e.g. genre tagging). The way it is usually done is that the original input is augmented in a natural way to create a so-called supervisory signal, which can play the role of an expert label in supervised learning. In image recognition tasks (e.g. is it a giraffe or not), a usual augmentation operation is rotation (e.g. rotating an input giraffe image by 45 degrees) and the model is expected to output a similar embedding of the original and the rotated giraffe images. In other words, the model will deem that both images picture a giraffe –which is naturally true as rotation doesn’t fundamentally alter the very content of an image.
Researchers at Deezer apply self-supervised learning for efficient genre tagging. In this article, which appeared last year at the IEEE International Conference on Acoustics, Speech and Signal Processing conference in Seoul, Korea (ICASSP 2024), the authors propose an approach to pre-train an AI model by feeding it pairs of 4-second snippets of the same audio track where the two snippets are “close enough” to each other, a form of so-called contrastive self-supervised learning. The rationale of closeness is that the context of the two snippets within the track should be the same so that the algorithm can classify the two snippets as similar in terms of applicable tags.
The paper compares contrastive learning with other forms of self-supervised learning and finds that it’s a superior method in terms of accuracy of tags prediction. As a result, the pre-trained model can be further trained using supervised learning with a lot less labeled data needed for high precision predictions.
A neat result, although I’m not sure how well the algorithm would do on this cult piece (thanks Feryne), where the style jumps left and right within a few seconds and if the snippets are from different “phases” of the track then self-supervision would introduce error.
Interestingly, the AI models used in this approach are so-called convolutional neural networks (CNNs), whose most typical applications have been in image processing tasks. The idea of CNNs is to drastically decrease the number of parameters compared to the conventional fully-connected nets, where each pixel of an image would be represented by one or more dedicated parameters. CNNs introduce a highly efficient form of parameter sharing based on the idea that different patches (or parts) of the same image can have similar information –such as edges of a shape or the dominant color of a region. Since audio can be naturally represented as an image, often as a Mel-spectogram – see cover image –, using CNNs for sound processing has become a go-to choice in AI applications.
Self-supervised tonality estimation
The tonality (or key) in music defines the notes used to compose a tune. Therefore, the key has a direct influence on how we hear and perceive music. For example, a DJ set which is “mixed in key”, meaning that adjacent tracks had been written in keys that are close to each other (i.e. they share a high number of notes) may sound smoother.
In music theory, the circle of fifths is a handy tool for various applications. For example, adjacent keys on the circle (e.g. C major and G major) share a majority of their notes. (For those who are interested, the legendary Michael New videos may be a good entry point into this not-so-easy material; you may want to start with this one on keys or this other one on the circle of fifths).
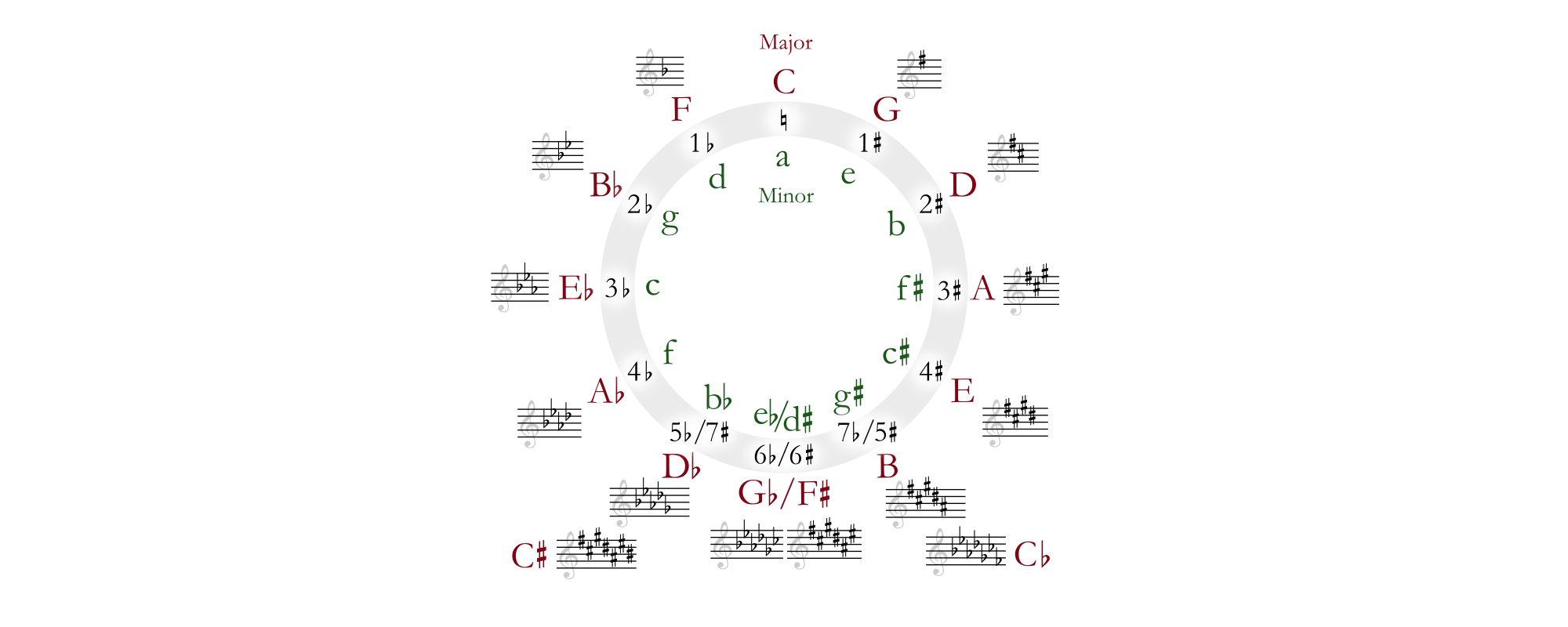
An expert ear may be able to decide if two pieces go “in tune” but it is not a trivial task for the machine, also because no big labeled datasets are available which would make supervised learning viable. Fortunately, self-supervised learning can be a remedy here as well, as proposed in this paper by researchers of Deezer and University of Nantes, published in 2024 at the International Society for Music Information Retrieval conference in San Francisco, USA (ISMIR 2024). The main idea is to use snippets of the same input audio data, transform them into different keys along the circle of fifths, and let the neural network learn a representation that correlates with the tonal key of the tune. Even though the absolute key of the tune is unknown, the algorithm constructs paired samples (of different tonality) in which relative harmonic progressions serve as a learning signal for tonality estimation. Then, after this so-called pretext task (a general term for the self-supervised learning phase), supervised learning can be applied, just like for music tagging above, to train a network based on the previously learned representation, for better accuracy and requiring considerably less training data.
Recommendations: Are they precise?
Another relevant challenge for DSPs is how to represent users in terms of interest areas so that recommendations can be placed efficiently. To do so, recommender systems need to derive higher-level concepts to classify users; a common approach is averaging the embedding of multiple tracks in a playlist or album and use this score to represent the taste or style of the collection and recommend similar artefacts that are numerically close to the base score.
In a paper appeared at ACM Conference on Recommender Systems in 2023 in Singapore (RecSys 2023), its authors from Deezer and University Paris Dauphine pose the question if the method of averaging results in good (in formal terms, consistent) recommendations. The idea to formalise consistency is that the closer the average embedding is to the embedding of the individual items the higher the consistency. For example, the score of an album cannot be “far away” from the tracks of the album.
It turns out the averaging method will not deliver consistent results with a growing number of items in the collection. The trend is visualised in the paper by the following graphs where k is the number of items taken from three different statistical distributions (corresponding to the three graphs). N depicts the number of all items in the measurement, simulating all tracks within a DSP.
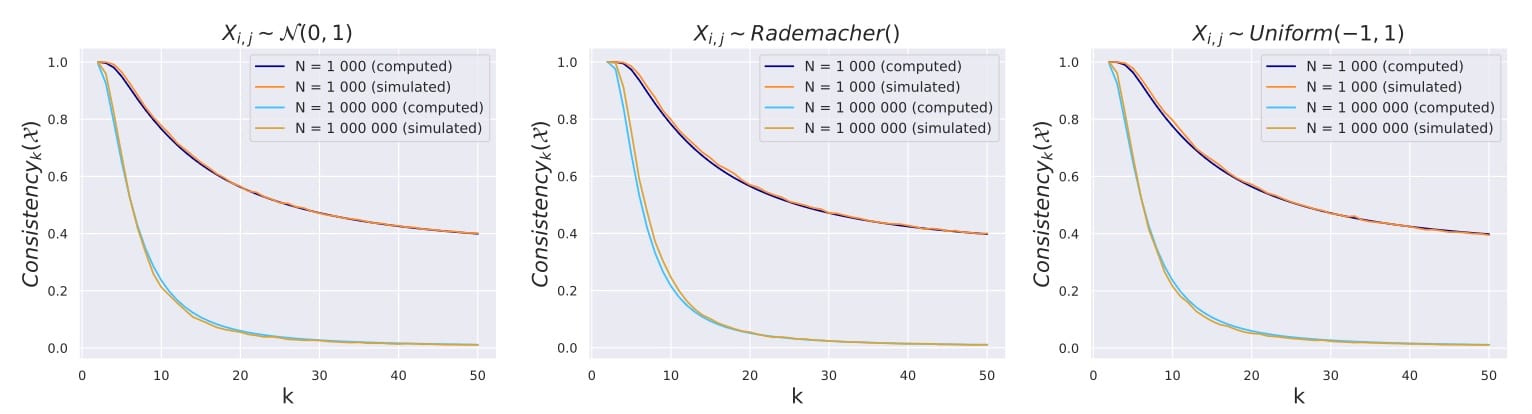
It is visible that starting with small values of k (around 10), consistency breaks down, meaning that the averaging method is pretty bad for real life scenarios. The situation seems better for small numbers of N, but that’s not a realistic configuration in actual DSPs.
Well, that’s not very good news for users of DSPs, is it. So, we recommend sticking with music journalism to gather your recommendations from ;)
AI-music detection
Sure enough, AI-generated music is the ultimate evil for a lot of music lovers, especially musicians. The two main factors of this hatred may be 1) being nervous about the job (of composing) being taken away and 2) worrying about copyright infringement (i.e. royalties not paid out albeit licensed material being used); and there are many other (socio-technical-political-cultural) aspects of modern generative AI usage (for and beyond music), which we will not cover now. What we’ll do is to try to figure out if a tune has been created using AI or not (aka AI music detection)?
To warm up, listen to the following audio snippets (source).
Do you notice any difference? These are not edits or remixes, that’s clear (they are too much alike). In fact, based on an original human-produced music, the following two versions have been encoded (by the way, into Mel-spectogram format) by algorithms commonly used in the main pipeline of generative music engines –for example, an Encodec-like autoencoder is used within the popular Suno platform’s machinery. For analysis purposes, the intermediate autoencoded representations have been reconstructed into the audible versions above. Arguably, the difference between the original vs Encoder version is not easy to catch by the human ear, which is an indication that it’s not trivial to tell whether a piece of music is AI-generated or not.
In a very recent paper, published at ICASSP 2025, Deezer Research has come up with a method for reliably detecting AI-music in certain settings. The observation is that using standard convolutional models (which are deep neural nets) and training them with pairs of audio data like above, e.g. the pair (original, Encodec version) and (original, GriffinMel version), the model can accurately predict whether or not the input music is AI-generated. The intuition is that the model learns to suspect AI-generation based on the reconstructions resulting from commonly known autoencodings.
Unfortunately, this naive detection approach is not very robust, as it is pointed out in the paper by the authors themselves, and they present a sophisticated analysis to characterise the robustness of the method. It turns out that if the audio is transformed (e.g. pitched) or another autoencoder is used, then the accuracy of the detection drops drastically.
Somewhat related is this gem by Benn Jordan, a real nerd and the man behind Flashbulb, where he develops a method to fool AI music generators so that they will generate non-sense as a continuation of the uploaded music (a common feature of platforms like Suno or Udio). Unfortunately, the method is very costly (in terms of time and energy needed to render these audio files) and, an aspect that the video doesn’t talk about, it is unclear how hard it is to detect such encodings. If it is easy, then AI music generators could simply reject such uploads. Plus, if there is an efficient way to transform the inputs into expected encodings, then the “attack” can be worked around easily.
Wrapping up, what’s the lesson of all this? First, I think it’s good that a company like Deezer is involved in such fundamental research and, it is even better, that they are so open about it (at least about some of the research they’re doing). Second, it feels a bit surprising how immature certain AI music features are (as pointed out by active and recent research papers listed just in this write-up), where one would think that, at a time supposedly close to ChatGPT-5, state-of-the-art AI would perform much better. So, to end on a positive note, there is no need to panic: technology is not yet saturated (i.e. there is room for innovation) and (some) jobs have not been taken away yet (e.g. if you’re able to tell a tune’s key by hearing it, you’re an asset).
No AI has been used to author this article.
Jelen cikk az EM GUIDE projekt keretein belül jött létre. Az EM GUIDE célkitűzése az európai független zenei magazinok támogatása, és underground zenei színterek erősítése. A projektről bővebben az emgui.de oldalon olvashattok.
Az Európai Unió finanszírozásával. Az itt szereplő vélemények és állítások a szerző(k) álláspontját tükrözik, és nem feltétlenül egyeznek meg az Európai Unió vagy az Európai Oktatási és Kulturális Végrehajtó Ügynökség (EACEA) hivatalos álláspontjával. Sem az Európai Unió, sem az EACEA nem vonható felelősségre miattuk.




